크롤링 중 링크태그인 a href 크롤링입니다.
SBS의 최신뉴스/속보 링크를 크롤링 해보겠습니다.
링크 : https://news.sbs.co.kr/news/newsflash.do?plink=GNB&cooper=SBSNEWS
SBS 최신 뉴스/속보
SBS 뉴스 - TV 뉴스, 날씨, 8뉴스, 모닝와이드, 나이트라인, 뉴스브리핑, 취재파일, 비디오머그, 스브스뉴스, 보이스, 등을 제공합니다.
news.sbs.co.kr
크롬 개발자도구(f12)를 사용하여 기사글의 div 위치를 확인합니다.
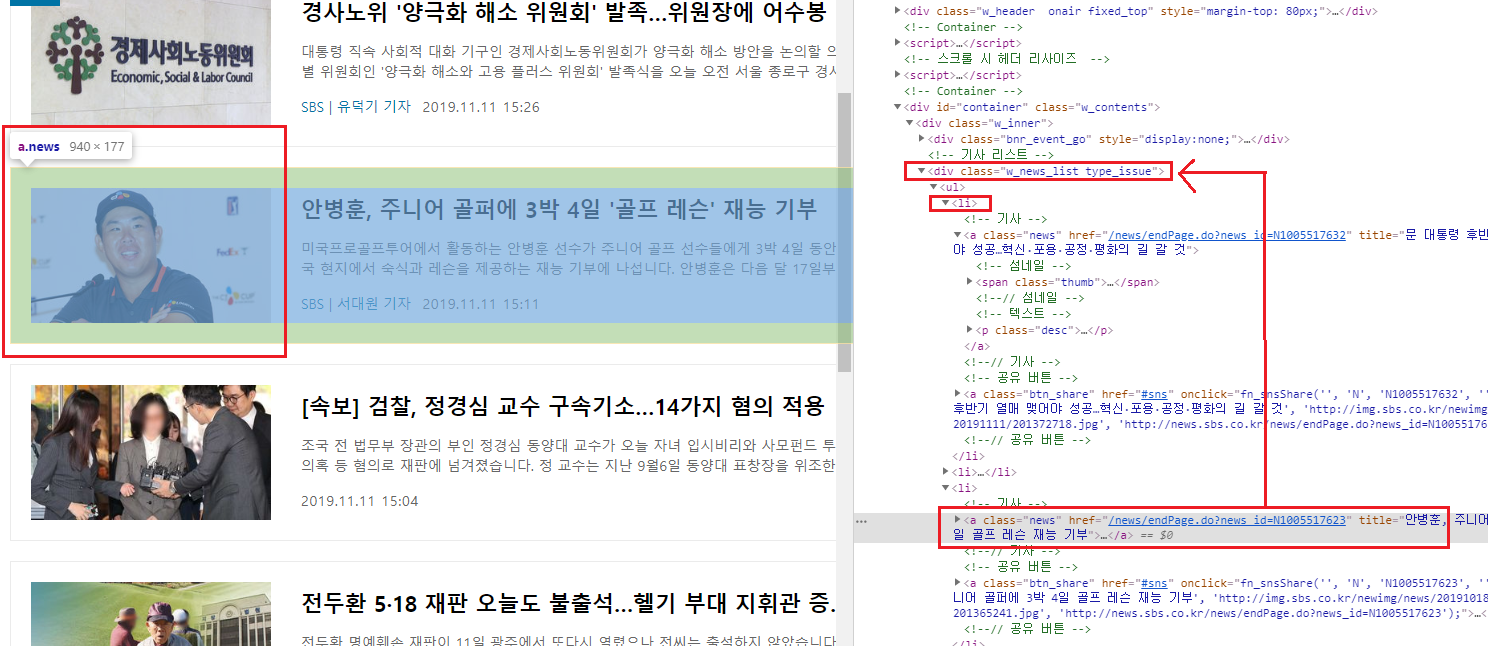
<div class="w_news_list type_issue"> 이 부분이 상위 div 클래스이며, 아래 li 마다 기사링크들이 있습니다.
beautifulsoup를 사용하여 프로그래밍을 해보면,
|
1
2
3
4
5
6
7
8
9
10
|
import urllib.request
from bs4 import BeautifulSoup
url = "https://news.sbs.co.kr/news/newsflash.do?plink=GNB&cooper=SBSNEWS"
req = urllib.request.Request(url)
sourcecode = urllib.request.urlopen(url).read()
soup = BeautifulSoup(sourcecode, "html.parser")
for href in soup.find("div", class_="w_news_list").find_all("li"):
print(href.find("a")["href"])
|
cs |
url은 위의 링크페이지이며,
for href in soup.find("div", class_="w_news_list").find_all("li"):
-> w_news_list type_issue 두개가 아닌 w_news_list 한가지만 가지고 찾습니다.
find_all("li"):
->위 w_news_list 찾은 후 li태그 부분만을 찾습니다.
print(href.find("a")["href"])
->위 li태그 중 a href 태그의 링크를 찾습니다.
Result:

위의 결과값으로 복사하여 접속하면, 접속이 안됩니다.

실제주소는 https://news.sbs.co.kr 주소가 앞에 붙어야합니다.

위의 코드를 수정하여,
|
1
2
3
4
5
6
7
8
9
10
|
import urllib.request
from bs4 import BeautifulSoup
url = "https://news.sbs.co.kr/news/newsflash.do?plink=GNB&cooper=SBSNEWS"
req = urllib.request.Request(url)
sourcecode = urllib.request.urlopen(url).read()
soup = BeautifulSoup(sourcecode, "html.parser")
for href in soup.find("div", class_="w_news_list").find_all("li"):
print("https://news.sbs.co.kr" + href.find("a")["href"])
|
cs |
위와 같이 수정하면,
결과 값은

어려우시거나 궁금하신점은 덧글로 남겨주세요.
'DevSpace > Python | Django' 카테고리의 다른 글
| [Python-Django] mysqlclient 설치시 오류 (0) | 2019.12.02 |
|---|---|
| [Django] DisallowedHost 웹페이지 접속에러 (0) | 2019.11.26 |
| [Python] 날짜 입력 받아 한국 양/음력 변환 (1) | 2019.11.12 |
| [Python] 한국 양/음력 변환 (0) | 2019.10.08 |
| [Python]파이썬 mysql DB조회 시 UnicodeDecodeError (1) | 2019.09.19 |



